by Matias Goldberg | Mar 14, 2016 | News
Whoa! Last time I (Matias) posted, we had a different website 🙂
What I’ve been working on:
I’ve started working on “Compute Shaders” (CS). They have been blocking future progress for far too long. They are required for modern techniques such as Forward+ and come in handy for things like tiled deferred rendering. Originally I started on compute shaders because I wanted them for a new terrain system that could generate the shadow maps in real time (yeah, there’s a new terrain system coming). CS are the only way to do it efficiently.
This has been a lot of work, and is currently under the unstable branch “2.1-pso-compute”. Actually, Compute Shaders are already working. However what we need to support is UAV buffers, which is sort of speak like read & write malloc’ed arrays of GPUs. We’ve already added support for UAV textures, but UAV buffers were missing and they are more flexible.
UAV buffers need to be treated with care though, because you’ll likely want to to create them from C++ (since they’re almost like a GPU malloc), but the compositor needs to be aware of them.
Why, you ask? Because the compositor is in charge of placing memory barriers and resource transitions. In other words: It needs to prevent race conditions. You’ll see … if you run Compute Shader A, and then Compute Shader B, and then render geometry, you have no guarantee that A will be completed before B. In fact, rendering geometry may even finish before A does!
This is great for GPU parallelism (colloquially known as Async Compute), but sucks if there were data dependencies (e. g. B depended on A, or Rendering Geometry depended on A or B). Memory barriers/resource transitions ensure shaders that must be run in order are executed in order while, hopefully, shader executions that are independent can run in parallel without being stalled.
Note: D3D11 implicitly inserts implicit memory barriers between compute shader executions, OpenGL only offers coarse memory barriers, but only Vulkan & D3D12 offer fine memory barriers.
The Compositor is in the best spot for this kind of work because it analyzes dependencies once (during workspace initialization) and can see all input, outputs and data dependencies.
That means that while UAV buffers can be created and managed from C++, some parts must be relinquished or informed to the compositor to ensure proper behavior (whether via scripts or via code). This means I need to be extremely careful with the design to avoid a clueless programmer innocently setting an UAV as input/output from a compute shader directly without the compositor noticing.
To make things worse, D3D11 & OpenGL differ quite greatly in how UAV buffers should be handled.
All in all, progress is steady. Compute Shaders are coming.
Other stuff that has increased in importance has been multiple RenderTarget inputs to compositor workspaces. Right now we only allow defining one “final target” which is treated as the final output (i. e. the RenderWIndow), although it doesn’t necessarily have to. The intention is to support more than just one external RenderTargets being available to a Compositor Workspace, which helps a lot in chaining multiple workspaces together (and are also very relevant for calculating memory barriers correctly).
Compute Shaders defined via JSON and have access to the Hlms
This is something I’ve been wanting to do for a while. Instead of using low level material’s syntax or interface (which was half ill-suited, half well-suited for the job), a new special Hlms is in charge of Compute shaders. We already have a working example (see all possible settings), although beware it’s subject to change. Auto params work, but not all of them since some don’t make sense because they were meant for rendering (and for the moment, attempting to use the unsuitable ones will likely result in a crash).
Why am I excited about the Hlms access? Because of the preprocessor of course!
For example, you can use the Hlms to unroll a loop based on the width of texture, thus reducing loop overhead during execution. Unrolling a loop can be critical in fully utilizing all bandwidth when performing certain tasks (such as parallel reduction), though it can hurt performance in other cases (particularly if the instruction length is too high, or it results in high register pressure).
You can also adapt your code based on the number of threads per group or automatically modify the shader depending on whether the bound texture is MSAA or not (which would normally require defining multiple shader programs and manually selecting the correct one).
What’s next?
Once Compute Shaders are over, I can finish what little remains of this terrain system and release it. Afterwards I may end up resuming on DERGO (a in-Blender live Ogre material editor) or continuing support for GLES3.
I really want to work more on DERGO, but GLES3 working again would mean three platforms being compatible again (OS X, Android, iOS) and once we have that in the bag, we might start talking about an official 2.1 SDK release date. Can’t say that isn’t tempting…
What else was accomplished in the past 2 months:
- User al2950 contributed PlaneBoundedVolumeSceneQuery to Ogre 2.x. This feature has been requested by many. Thanks!
- spookyboo deserves a special mention for reporting a lot of JSON bugs for our PBS materials. He has been severely stress testing our system as he’s been working on a Hlms material editor.
- A major bug involving reading of normal maps was fixed. Thanks to user GlowingPotato for noticing!
- Several fixes affecting the accuracy of our PBS implementation.
- Other minor bug fixes.
Thanks to all community users who have been reporting your issues and helping make Ogre 2.1 more robust every day! Our PBS implementation has been under a lot of scrutiny lately and I like it. It hurts my ego of course, but it results in improved quality. This of course means our users can focus on the important parts and not on the technical details.
by Matias Goldberg | Jul 8, 2015 | News
A little late report. We know we missed April & May in the middle. But don’t worry. We’ve been busy!
So…what’s new in the Ogre 2.1 development branch?
1. Added depth texture support! This feature has been requested many times for a very long time. It was about time we added it!
Now you can write directly to depth buffers (aka depth-only passes) and read from them. This is very useful for Shadow Mapping. It also allows us to do PCF filtering in hardware with OpenGL.
But you can also read the depth buffers from regular passes, which is useful for reconstructing position in Deferred Shading systems, and post-processing effects that need depth, like SSAO and Depth of Field, without having to use MRT or another emulation to get the depth.
We make the distinction between “depth buffer” and “depth textures”. In Ogre, “depth textures” are buffers that have been requested to be read from as a texture at some point in time. If you want to ever use it as a texture, you’ll want to request a depth texture (controlled via RenderTarget::setPreferDepthTexture).
A “depth buffer” is a depth buffer that you will never be reading from as a texture and that can’t be used as such. This is because certain hardware gets certain optimizations or gets more precise depth formats available that would otherwise be unavailable if you ask for a depth textures.
For most modern hardware though, there’s probably no noticeable performance difference in this flag.
(more…)
by Matias Goldberg | Apr 5, 2015 | News
This is dark_sylinc writing again! Wanna know what we’ve been up to? Well, here it comes:
1. Improved shadow mapping quality. The PCF code I used was some snippet I had lying around since 2008. I now finally sat down and implemented better approaches.
Before:

After (same quality):
After (highest quality):

You can look in the forum thread for more information. Some community members have also posted more snippets with different filters. Some of these other filters may be provided out of the box eventually.
2. Hot reloading of Hlms shader templates: This has been supported for a while, but never publicly mentioned and the microcode cache could get in the way. This is very useful for more productive development, iteration, and debugging of Hlms shader files. In the samples, hit Ctrl+F1 to reload the PBS shaders and Ctrl+F2 to reload the Unlit shaders.
3. Fixed lots, lots and lots of D3D11 errors: Back in the previous report, we’ve described that DX11 had been ported. But there were still crashes lingering around, low level materials weren’t working, lots of texturing and mipmapping errors, huge memory leaks, and many other misc. errors. We’re happy and proud to say they’ve been fixed. There’s probably a few more bugs around waiting to be discovered and fixed…just like everything else.
4. Ogre 2.1 tested on Intel cards! I’ve only tested on an Intel HD 4600 so far and for GL3+ to work you will need the very latest drivers. Intel’s D3D11 support has always been significantly superior, and Ogre is no exception to that rule. If you intend to target the Intel market share of GPUs, shipping with D3D11 is a requirement.
Note: Remember that for other vendors, GL3+ can improve performance significantly over D3D11 as well! Don’t assume one particular API is superior for everybody!
Aside from these features, we’ve been fixing bugs, improving stability, improving documentation and tweaking the engine based on community feedback (thank you guys!). Ogre 2.1 keeps getting better every day.
Two community members made an awesome forum post where they took our PBS shaders and modified them to get a similar look to Marmoset Toolbag 2 (a non-Ogre-related 3rd-party tool for editing physically based materials). We’re looking forward into evaluating their improvements and integrating them into Ogre 2.1. We believe that the interoperability with industry-standard 3rd party tools such as Marmoset is key for the future of Ogre. You’ll probably hear from us about this in the next report, or the next to that one.
Well, that’s all for now. If you’ll excuse me, I need to go back to my cave 🙂 …
by Matias Goldberg | Mar 5, 2015 | News
This is dark_sylinc writing again…and: Oh boy! We’ve been busy!
1. Light list generation for forward lighting was threaded. Turns out, we were spending a lot of time building the light list when there are tons of objects on screen. Frame time was reduced from 10 ms to 4.5 ms on my Intel i5-4460 for 50k draws (AMD Radeon HD 7770).
2. Ported DX11! It’s not as thoroughly tested as the GL3+ RenderSystem, so I’d stick with GL3+ if you want stability. But it’s booting up, it can take advantage of most of the AZDO enhancements, and all the samples are running. Performance benchmarks against GL3+ are inconsistent: It highly depends on the driver (different cards, different bench results) and some samples run better on GL3+ others on D3D11, but often only by a slight margin.
Since the samples are GPU bottlenecked, my theory is that it depends on how well the driver compiles and optimizes the GLSL shader versus how well the driver optimizes and reinterprets the HLSL IL that the D3D runtime throws at the driver.
Now cards that are supposed to be supported but were not due to driver issues (i. e. Radeon HD 2000 through Radeon HD 4000) are now being supported! Intel cards weren’t tested, but in theory they should be supported too. Feedback is appreciated in this area (both Windows, Linux, and D3D vs. OpenGL).

GL to the left, D3D to the right. The FPS difference isn’t relevant and can go either way.
3. We’ve been working on an experimental branch with a new technique called “Forward3D“. Sounds exciting but it’s not really ground breaking.
I don’t want to use deferred shading as default because it causes a lot of problems (transparency, antialiasing, multiple BDRF). Besides, it uses a lot of bandwidth. Forward+/Forward2.5 is great, but requires DX11 HW (needs UAV) and a Z-Prepass. This Z-prepass is often a turn off for many (even though in some cases it may improve performance, i.e. if you’re heavily pixel shader or ROP [= raster operation] bound).
I came up with an original idea for a new algorithm I call “Forward3D“. It’s not superior on all accounts, but it can work on DX10 hardware and doesn’t require a Z-prepass. The light list generation algorithm is now being generated in the CPU, however I think it should be able to run on Compute Shaders on DX10 hardware just fine (though, I don’t know yet if generating the light list is expensive enough; it may not even be worth doing on CS or perhaps it will).
The result is a nice generic algorithm that can run on a lot of hardware and can handle a lot of lights. Whether it performs better or worse than Deferred or Forward+ depends on the scene.
These are early screenshots. The algorithm has actually improved since then (particularly for bigger lights, it can handle a lot more lights now):
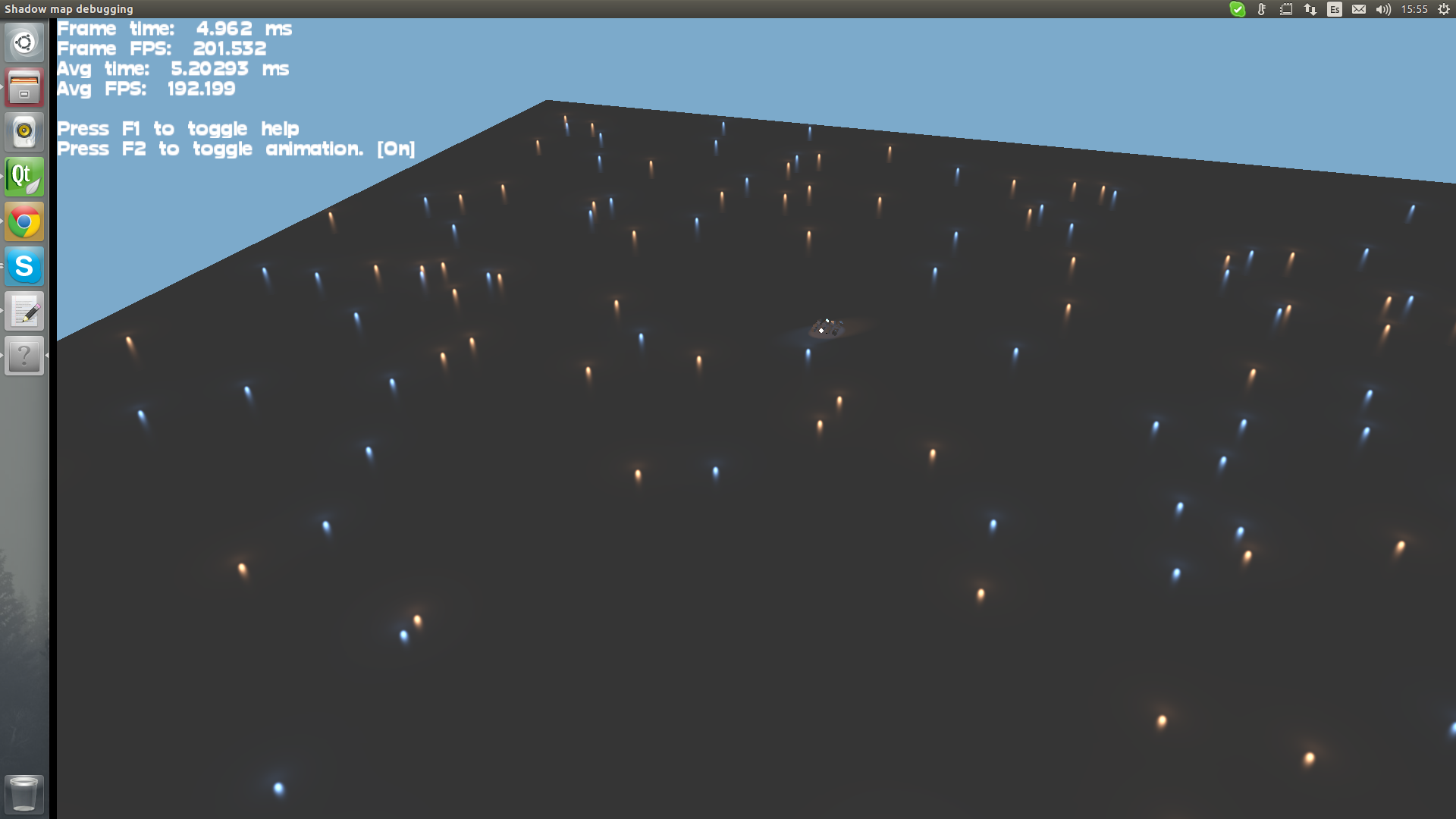
Forward3D in action. Many small lights = OK. Few big lights = OK. Many bigger lights = Not ok.

With bigger lights they start getting LOD’ed as a side effect of how the algorithm works
4. The community seems to be eager to compare how Ogre 2.1 fares against commercial engines. Remember that Ogre is a rendering engine while most of these engines are game engines (which means they provide much more than graphics, like physics, sounds, logic, scripting and level editors). Nonetheless Ogre seems to be doing very well!
We highly appreciate the faith you put in us!
5. Reported two Linux driver bugs to AMD. AMD has already confirmed that they will be including a fix for one of their bugs in the next Linux release. Their engineers are still working on the second bug, which has been much harder to isolate.
6. Merged all changes from:
- 1.9 → 1.10
- 1.9 & 1.10 → 2.0
- 1.9 & 1.10 & 2.0 → 2.1
Now, all enhancements that were made to 1.10 (particular to RenderSystems) are available in 2.0 as well. We still recommend that on 2.0 you stick to D3D9 though, since it’s the fastest and most stable one. On 2.1 we recommend GL3+, but you’re now encouraged to also try out the D3D11 RS as well.
7. Fixed tons of bugs as they’ve been reported or been found.
Well. There’s a lot of work that remains to be done. Ogre3D is well and alive! I’m /signing off for now.
by Murat Sari | Feb 10, 2015 | News
Hello everybody, Murat (wolfmanfx) here:
Last year at CodeRabbit GmbH (my own company), we started a project called “Distributed Viewer”.
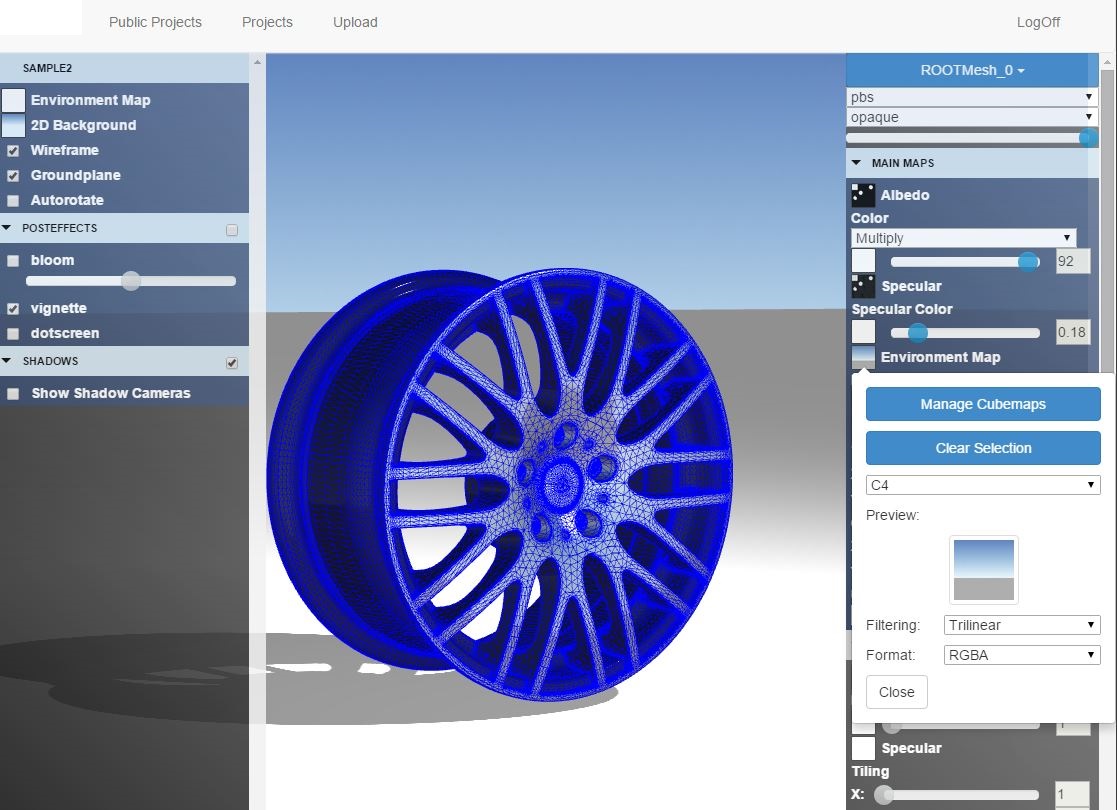
Distributed Viewer is an editor where users can upload models and edit materials in real time from any browser and instantly preview the changes not only in the browser, but also in all connected devices such as desktop PCs, Android and iOS devices at the same time.
Early in the development cycle we have realized that the current Ogre material system was too limiting and too complicated to do something like this. So after many discussions we came to the point where we decided to fund the initial development of the Ogre HLMS “High Level Material System”. More details about the HLMS can be found in this post from Matias.
With HLMS in our bag we have created PBS (Physically Based Shading) materials for the uploaded models. Our PBS shader is based on this moving-frostbite-to-pbr (the HLMS files will be released with the upcoming backport). The following image shows a screenshot from the material designer.

(more…)