
News
Ogre 13.4 released
![]() Ogre 13.4.0 was just released. This release contains some significant bug-fixes and feature additions, which we will discuss in more detail below. We recommend all users of the 13.x branch to update.
Ogre 13.4.0 was just released. This release contains some significant bug-fixes and feature additions, which we will discuss in more detail below. We recommend all users of the 13.x branch to update.
Table of Contents
- Extended PBR-material support
- Bullet Integration now available as a Component
- VET_INT_10_10_10_2_NORM support added
- Other Additions
For a full overview of the changes, see the changelog.
Extended PBR-material support
with blender 2.8+ and blender2ogre 0.8.3, you can now choose to export PBR metal-roughness parameters instead of converting them to a FFP approximation as before.
While at it, several bugs in the RTSS PBR implementation were fixed. Now transparency, ambient lighting and PSSM shadows play nicely with PBR.
Bullet Integration now available as a Component
In the User Survey btogre was the most popular external Ogre component with over 53% votes.

To make life for those who use it easier, it is now integrated into the main repo as a component. This allows you to just build it as part of Ogre on one hand and on the other hand this ensures that it is integration tested by our CI.
VET_INT_10_10_10_2_NORM support added
Ogre now supports normalized INT_10_10_10_2 as the vertex format. This packs 3 signed values with 10bit precision and a fourth 2bit value into 4 bytes – the size required by a single float.
If you are using normal-maps, you will notice how this format is perfect to store a tangent with parity, while only requiring 25% of storage compared to 4 floats.
Additionally, you can use it to store normals where storage requirements drop to 33% too.
In both cases the 10bit resolution is typically sufficient.
The format is natively supported by GLES3, GL3+, Vulkan and Metal meaning that you also save bandwidth and VRAM.
With the other RenderSystems, Ogre will transparently unpack the data to float at mesh load time, so you at least can benefit from smaller mesh files.
E.g. a 76 MB mesh can be reduced to 50 MB, when using packed normals and tangents.
To update your meshes, OgreMeshUpgrader gained the option -pack, to be used like:
OgreMeshUpgrader -pack your.meshOther Additions
In other news Bites Input now not only handles Gamepads but generic Joysticks and Ogre can be used online through Google Colab.
Ogre 13 User Survey Results
During the period of Jan 10. – February 10. we received 54 replies. At the same time the ogre 13.2.4 Windows SDK alone was downloaded 2188 times. So while the results are insightful, they are probably not representative.
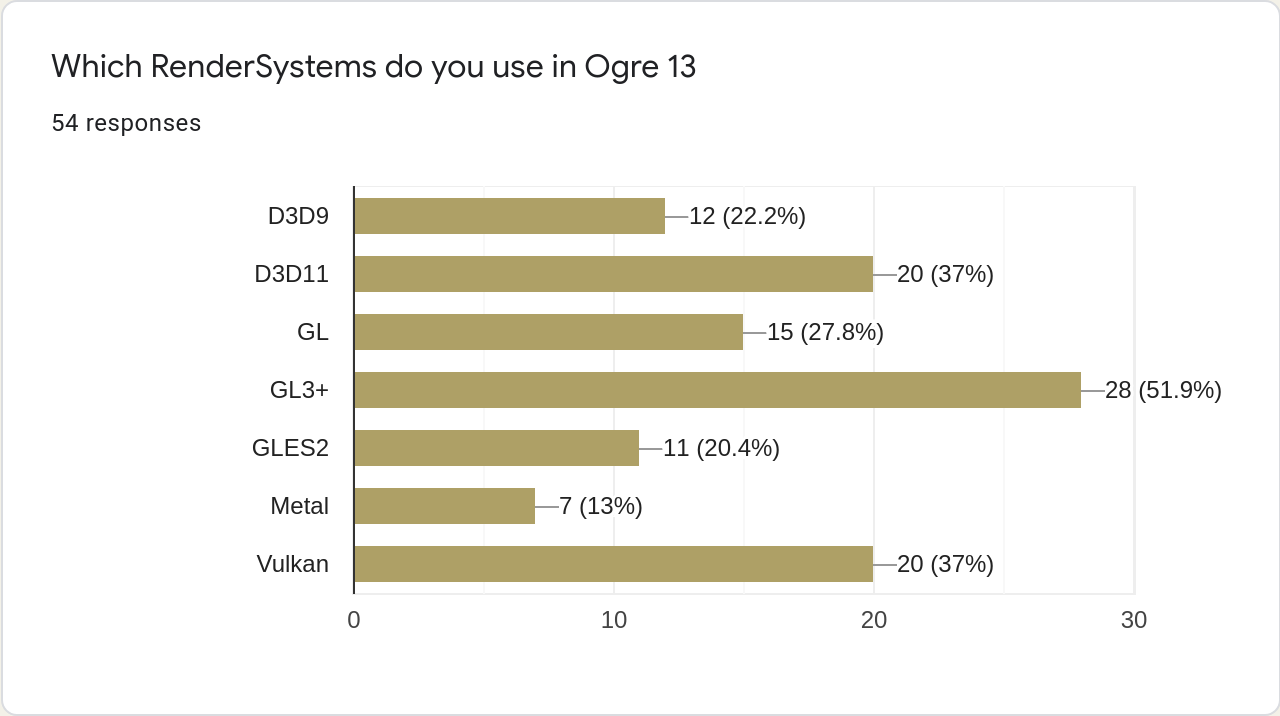
When it comes to RenderSystems, we finally see a significant drop for the legacy systems (D3D9, GL). This will allow us to focus on new features only supported on modern APIs. However, I doubt the numbers for Vulkan, given how recent the Vulkan addition was.
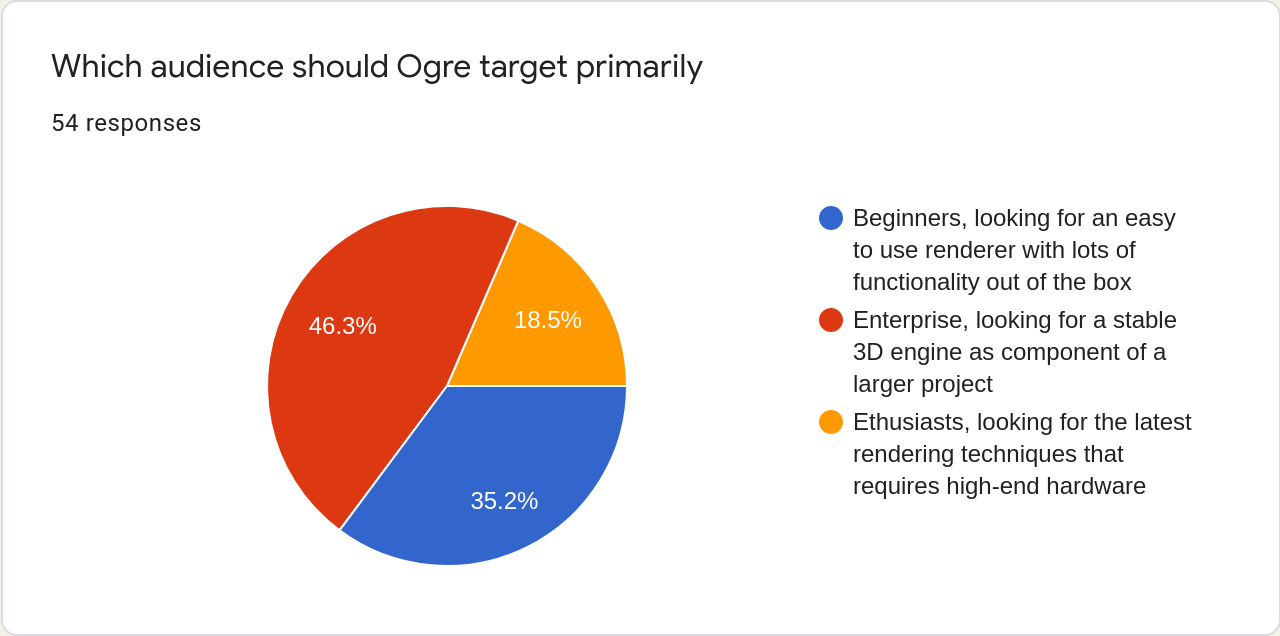
The most relevant result for further development is likely the question of target audience. Here, we see an increase of the enthusiast portion at the cost of the Enterprise one. I take it as we can sacrifice some API stability to gain modern rendering techniques when moving forward.
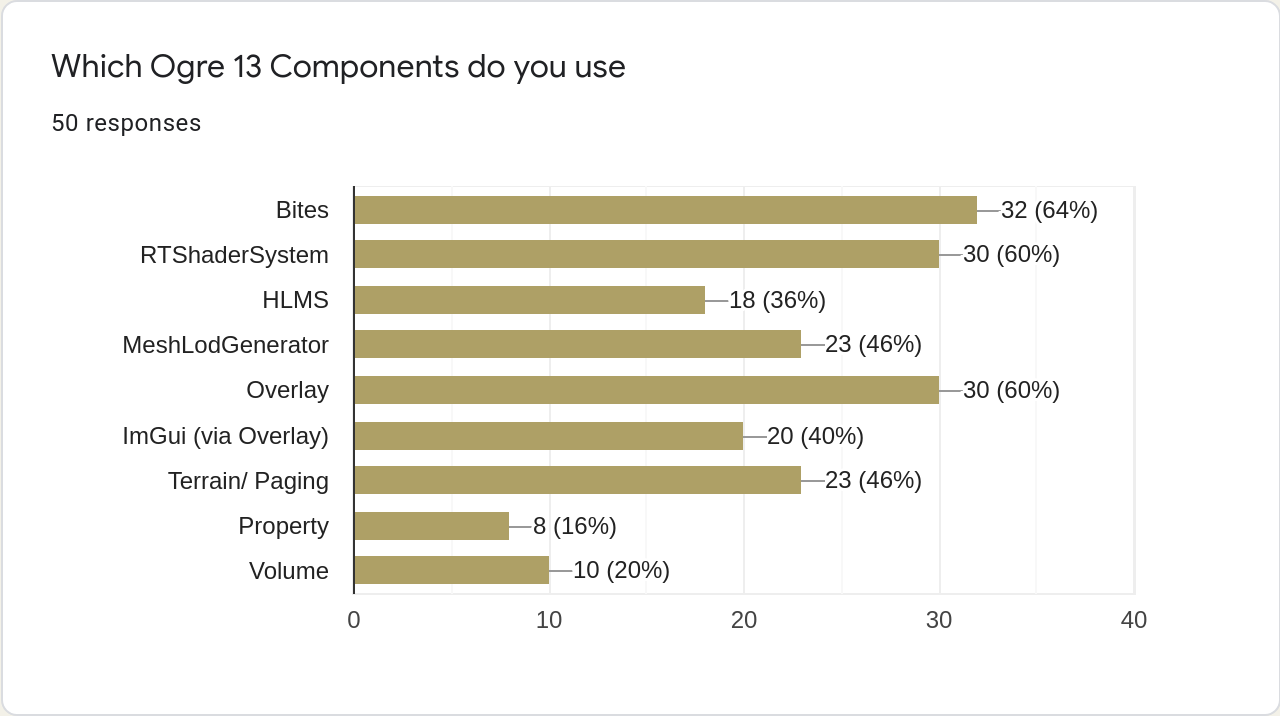
The following one is also interesting, as the HLMS was dropped with Ogre 13 and the inclusion in the poll is a copy/ paste error. I guess that any component with less than 18 votes is not actually used, but people were merely ticking every option.
As always statistics are lies though, so better take a look at the actual numbers yourself.
Specific replies
Following the #MeanTweets idea I also wrote some short replies to the criticism, that you can read below:
read more…Ogre 13.3 released
![]() Ogre 13.3.0 was just released. This release contains some significant feature additions, which we will discuss in more detail below.
Ogre 13.3.0 was just released. This release contains some significant feature additions, which we will discuss in more detail below.
Table of Contents
For a full overview of the changes, see the changelog.
PBR Material support
The most significant addition is probably built-in PBR support via the RTSS.

To enable the PBR pipeline via material scripts, specify
rtshader_system
{
lighting_stage metal_roughness texture Default_metalRoughness.jpg
}The parameters are expected to be in the green and blue channels (as per glTF2.0) and lighting will be done according to the Filament equations.
Alternatively, you can use material-wide settings, by omitting the texture part like:
rtshader_system
{
lighting_stage metal_roughness
}Here, metalness is read from specular[0] and roughness from specular[1].
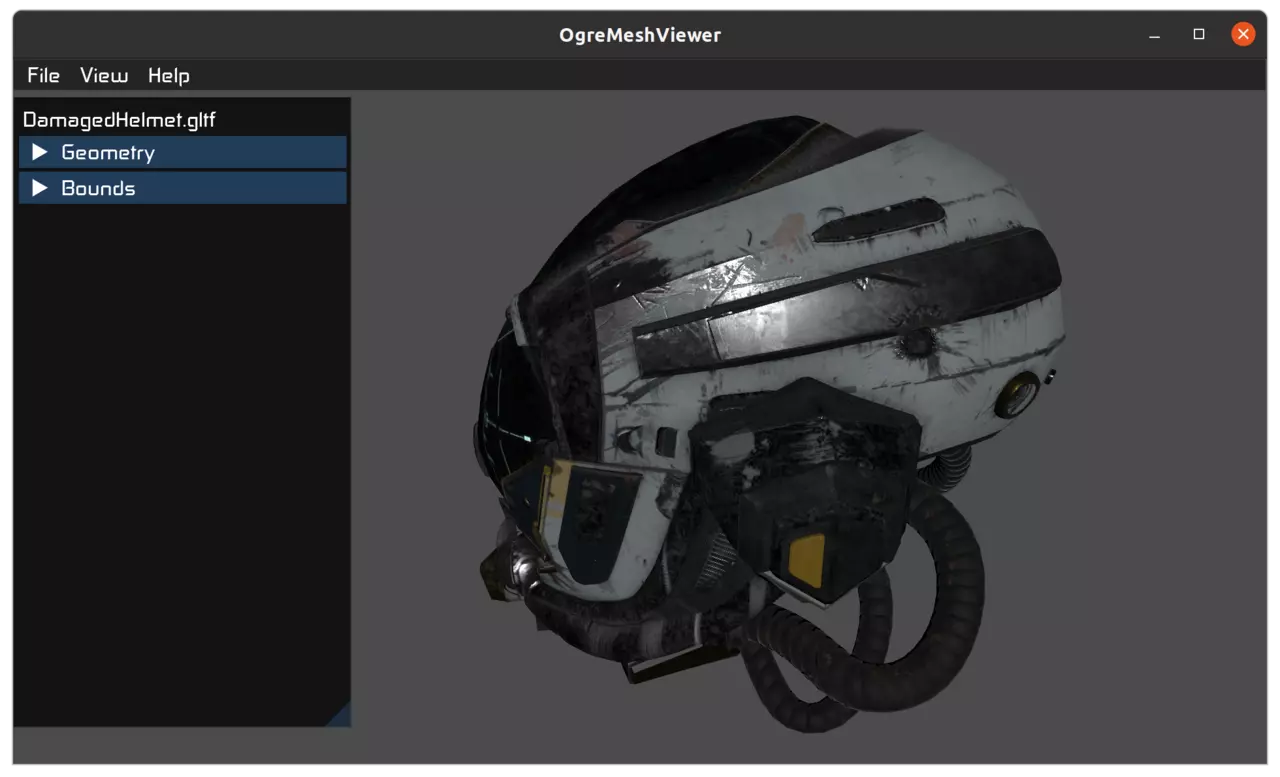
Furthermore, the Assimp Plugin will automatically use the PBR pipeline, if it encounters any PBR maps. This in turn allows correctly loading and displaying glTF2 meshes – as shown in the ogre-meshviewer screenshot above.
Improved Gamepad Support
The Gamepad Support in OgreBites (via SDL2) has been improved. Now the according events are correctly delegated to ImGui, so you can control the UI with your gamepad.
Also additional gamepad mappings can be specified by placing a gamecontroller.txt in the working directory.
Ogre 13 User Survey 2022
![]() Those of you who have been around Ogre for some time might remember that back in 2020, we conducted a survey about our user base. The results of which can be found here.
Those of you who have been around Ogre for some time might remember that back in 2020, we conducted a survey about our user base. The results of which can be found here.
For the Ogre 13 development cycle we would like to assess to correctly emphasize the development on the most used features.
So for the next four weeks until the 10th of February, you have the chance to participate and help us to get an impression about our user base, how Ogre is used and share some wishes for the future. Simply follow the link and make your way through the 14 questions. It should not take up much time since most of the questions are simple checkbox or radio button questions.
We want to thank you all upfront for helping us to develop Ogre further and getting some valuable insight information about the people using the engine!
PS: We would be glad if you could spread the word about the survey via all available channels to all potential Ogre users, because: The more participants, the more accurate are the results of course.
Removing bloat and reducing size in Ogre Next 2.4 by up to 20%
As we mentioned last time, Ogre-Next 2.4 will be mostly focusing on maintenance and fixing code debt.
Over a week we’ve fixed a lot of warnings.
With default settings on Clang on Linux, there’s no errors (except on OgreMeshTool).
But we haven’t taken a look at deprecated warnings yet.
On Apple/XCode and MSVC there’s very few warnings now
GCC needs Wconversion off because it’s incredibly dumb. It’s got too many false positives.
Fixing them would hurt readability too much, causing more harm than good.
Some CMake settings may cause warnings, e.g. we generate lots of warnings if OGRE_CONFIG_DOUBLE is on.
We also applied clang format to everything, and added C++11 override everywhere.
We’ve also removed dead code and added an option to turn off custom memory allocators off which is the default.
We’ve removed Boost, thus CMake won’t waste its time (and that was a lot) looking for an optional dependency we didn’t really need anymore.
Overall in Debug builds we’re seeing a 20% reduction in binary size (incl. symbols)!!
While Release builds have between 1% and 3% reductions.
The only drawback is that merging code 2.3 -> 2.4 is now harder as it’s almost guaranteed to cause a merge conflict, since nearly every line got touched.
Nonetheless it seems that merging by “merge using always theirs”, then applying clang format, then seeing the diff of what’s going to be merge is a good approach to prevent bad merges and fix accidentally introducing bugs
The numbers are in MBs
Linux Clang 9 – Debug
|
Lib Name |
Before (2.3) |
After (2.4) |
Diff |
|
libOgreHlmsPbs_d.so |
8,69 |
7,53 |
-15,48 % |
|
libOgreHlmsUnlit_d.so |
1,92 |
1,59 |
-20,48 % |
|
libOgreMain_d.so |
65,00 |
55,01 |
-18,17 % |
|
libOgreMeshLodGenerator_d.so |
4,27 |
3,71 |
-15,11 % |
|
libOgreOverlay_d.so |
3,87 |
3,30 |
-17,23 % |
|
libOgreSamplesCommon_d.a |
10,80 |
9,10 |
-18,64 % |
|
libOgreSceneFormat_d.so |
2,55 |
2,03 |
-25,44 % |
|
Plugin_ParticleFX_d.so |
1,79 |
1,63 |
-9,85 % |
|
RenderSystem_GL3Plus_d.so |
6,97 |
5,23 |
-33,25 % |
|
RenderSystem_NULL_d.so |
1,70 |
1,35 |
-25,87 % |
|
RenderSystem_Vulkan_d.so |
15,82 |
14,63 |
-8,18 % |
|
|
|
|
|
|
Total |
123,39 |
105,12 |
-17,39 % |
Linux Clang 9 – Release
|
Lib Name |
Before (2.3) |
After (2.4) |
Diff |
|
libOgreHlmsPbs.so |
0,80 |
0,78 |
-3,03 % |
|
libOgreHlmsUnlit.so |
0,19 |
0,19 |
-3,58 % |
|
libOgreMain.so |
7,31 |
6,93 |
-5,61 % |
|
libOgreMeshLodGenerator.so |
0,24 |
0,22 |
-5,21 % |
|
libOgreOverlay.so |
1,00 |
1,00 |
-0,14 % |
|
libOgreSamplesCommon.a |
0,43 |
0,41 |
-3,85 % |
|
libOgreSceneFormat.so |
0,23 |
0,23 |
0,95 % |
|
Plugin_ParticleFX.so |
0,25 |
0,24 |
-5,38 % |
|
RenderSystem_GL3Plus.so |
0,85 |
0,76 |
-11,86 % |
|
RenderSystem_NULL.so |
0,16 |
0,16 |
-0,94 % |
|
RenderSystem_Vulkan.so |
7,93 |
7,91 |
-0,22 % |
|
|
|
|
|
|
Total |
19,40 |
18,83 |
-3,02 % |
MSVC 2019 – Debug
|
Lib Name |
Before (2.3) |
After (2.4) |
Diff |
|
OgreHlmsPbs_d.dll |
1,89 |
1,82 |
-3,45 % |
|
OgreHlmsPbs_d.pdb |
15,53 |
12,82 |
-21,15 % |
|
OgreHlmsUnlit_d.dll |
0,47 |
0,45 |
-4,50 % |
|
OgreHlmsUnlit_d.pdb |
9,51 |
6,89 |
-37,96 % |
|
OgreMain_d.dll |
24,28 |
22,81 |
-6,45 % |
|
OgreMain_d.pdb |
101,56 |
81,94 |
-23,94 % |
|
OgreMeshLodGenerator_d.dll |
1,02 |
0,98 |
-4,90 % |
|
OgreMeshLodGenerator_d.pdb |
10,57 |
8,64 |
-22,34 % |
|
OgreMeshTool_d.pdb |
11,95 |
8,66 |
-37,98 % |
|
OgreOverlay_d.dll |
1,77 |
1,75 |
-1,45 % |
|
OgreOverlay_d.pdb |
13,28 |
9,50 |
-39,70 % |
|
OgreSceneFormat_d.dll |
0,58 |
0,57 |
-1,78 % |
|
OgreSceneFormat_d.pdb |
11,07 |
8,04 |
-37,82 % |
|
Plugin_ParticleFX_d.dll |
0,39 |
0,37 |
-5,59 % |
|
Plugin_ParticleFX_d.pdb |
6,18 |
5,12 |
-20,59 % |
|
RenderSystem_Direct3D11_d.dll |
2,02 |
1,90 |
-6,32 % |
|
RenderSystem_Direct3D11_d.pdb |
17,13 |
14,11 |
-21,37 % |
|
RenderSystem_GL3Plus_d.dll |
2,00 |
1,69 |
-18,41 % |
|
RenderSystem_GL3Plus_d.pdb |
16,17 |
12,25 |
-32,03 % |
|
RenderSystem_NULL_d.dll |
0,39 |
0,36 |
-8,09 % |
|
RenderSystem_NULL_d.pdb |
8,96 |
6,26 |
-43,04 % |
|
RenderSystem_Vulkan_d.dll |
17,69 |
17,58 |
-0,66 % |
|
RenderSystem_Vulkan_d.pdb |
104,54 |
87,89 |
-18,94 % |
|
OgreSamplesCommon_d.lib |
12,83 |
11,63 |
-10,28 % |
|
OgreSamplesCommon_d.pdb |
7,74 |
6,78 |
-14,18 % |
|
|
|
|
|
|
Total |
399,51 |
330,81 |
-20,77 % |
MSVC 2019 – Release
|
Lib Name |
Before (2.3) |
After (2.4) |
Diff |
|
OgreHlmsPbs.dll |
0,55 |
0,55 |
0,09 % |
|
OgreHlmsUnlit.dll |
0,14 |
0,13 |
-1,45 % |
|
OgreMain.dll |
6,91 |
6,82 |
-1,32 % |
|
OgreMeshLodGenerator.dll |
0,20 |
0,21 |
2,12 % |
|
OgreOverlay.dll |
0,71 |
0,71 |
-0,28 % |
|
OgreSceneFormat.dll |
0,17 |
0,17 |
0,00 % |
|
Plugin_ParticleFX.dll |
0,14 |
0,14 |
0,35 % |
|
RenderSystem_Direct3D11.dll |
0,52 |
0,51 |
-0,38 % |
|
RenderSystem_GL3Plus.dll |
0,59 |
0,54 |
-9,37 % |
|
RenderSystem_NULL.dll |
0,12 |
0,12 |
-2,54 % |
|
RenderSystem_Vulkan.dll |
3,81 |
3,80 |
-0,18 % |
|
OgreSamplesCommon.lib |
1,48 |
1,41 |
-4,72 % |
|
|
|
|
|
|
Total |
15,33 |
15,11 |
-1,44 % |
That’s all for now. Ogre 2.3 was released just a week ago and we wanted to share such an exciting development already happening on 2.4.
Discussion in forum thread.
Ogre-Next 2.3.0 Deadalus Released and Merry Christmas!
First of all, Merry Christmas to all those who celebrate it on behalf of the OGRE Team! (and if you don’t, have a nice day too!)
Second, after a bit more than a year in development, Ogre-Next 2.3.0 is released!
Magnificent work on Device Lost handling by Eugene Golushkov!
Most games don’t care too much about device lost because games can assume they own almost the entire computer while they’re running, and nothing else will be happening. A device lost is considered a critical failure and very uncommon, typically because of a Hardware or Software malfunction. Or a Windows Update in the middle of a gaming session, in which case the gaming experience is already interrupted anyway.
However this is not true for non-gaming apps: device lost can happen because of multiple reasons, but the two most common are:
- The graphics driver is upgraded
- Switching from power saving mode to performance or viceversa (mostly on laptops or other mobile devices)
Due to these two reasons, device lost becomes an almost certainty for long-running applications that could encounter a graphics driver suddenly upgrading; or for mobile/laptop-oriented applications where power mode switching can be very frequent.
Recovering from device lost can range from very easy to very difficult; depending on the complexity of an application and what the application was doing at the time the device was lost.
Eugene’s work goes to great lengths to try to gracefully recover from a Device Lost.
Switch importV1 to createByImportingV1
In 2.2.2 and earlier we had a function called Mesh::importV1 which would populate a v2 mesh by filling it with data from a v1 mesh, effectively importing it.
In 2.2.3 users should use MeshManager::createByImportingV1 instead. This function ‘remembers’ which meshes have been created through a conversion process, which allows device lost handling to repeat this import process and recreate the resources.
Aside from this little difference, there are no major functionality changes and the function arguments are the same.
Shadow’s Normal Offset Bias
We’ve had a couple complaints, but it wasn’t until user SolarPortal made a more exhaustive research where we realized we were not using state of the art shadow mapping techniques.
We were relying on hlmsManager->setShadowMappingUseBackFaces( true ) to hide most self-occlussion errors, but this caused other visual errors.
Normal Offset Bias is a technique from 2011 (yes, it’s old!) which drastically improves self occlussion and shadow acne while improving overall shadow quality; and is much more robust than using inverted-culling during the caster pass.
Therefore this technique replaced the old one and the function HlmsManager::setShadowMappingUseBackFaces() has been removed.
Users can globally control normal-offset and constant biases per cascade by tweaking ShadowTextureDefinition::normalOffsetBias and ShadowTextureDefinition::constantBiasScale respectively.
You can also control them via compositors scripts in the shadow node declaration, using the new keywords constant_bias_scale and normal_offset_bias
Users porting from 2.2.x may notice their shadows are a bit different (for the better!), but may encounter some self shadowing artifacts. Thus they may have to adjust these two biases if they need to.
Unlit vertex and pixel shaders unified
Unlit shaders were still duplicating its code 3 times (one for each RenderSystem) and all of its vertex & pixel shader code has been unified into a single .any file.
Although this shouldn’t impact you at all, users porting from 2.2.x need to make sure old Hlms shader templates from Unlit don’t linger and get mixed with the new files.
Pay special attention the files from Samples/Media/Hlms/Unlit match 1:1 the ones in your project and there aren’t stray .glsl/.hlsl/.metal files from an older version.
If you have customized the Unlit implementation, you may find your customizations to be broken. But they’re easy to fix. For reference look at Colibri’s two commits which ported its Unlit customizations from 2.2.x to 2.3.0
Added HlmsMacroblock::mDepthClamp
It is now possible to toggle Depth Clamp on/off. Check if it’s supported via RSC_DEPTH_CLAMP. All desktop GPU should support it unless you’re using extremely old OpenGL drivers.
iOS supports it since A11 chip (iPhone 8 or newer)
Users upgrading from older Ogre versions should be careful their libraries and headers don’t get out of sync. A full rebuild is recommended.
The reason being is that HlmsMacroblock (which is used almost anywhere in Ogre) added a new member variable. And if a DLL or header gets out of sync, it likely won’t crash but the artifacts will be very funny (most likely depth buffer will be disabled).
Added shadow pancaking
With the addition of depth clamp, we are now able to push the near plane of directional shadow maps in PSSM (non-stable variant). This greatly enhances depth buffer precision and reduces self-occlusion and acne bugs.
This improvement may make it possible for users to try using PFG_D16_UNORM instead of PFG_D32_FLOAT for shadow mapping, halving memory consumption.
Shadow pancaking is automatically disabled when depth clamp is not supported.
Vulkan is ready!
In Ogre-Next 2.3, Vulkan is considered stable. If you find a bug, please report it.
Most notable known issue is that it appears there are some issues when integrating with Qt we haven’t looked into yet.
PluginOptional
Old timers may remember that Ogre could crash if the latest DirectX runtimes were not installed, despite having an OpenGL backend as a fallback.
This was specially true during the Win 9x and Win XP eras which may not have DirectX 9.0c support. And stopped being an issue in the last decade since… well everyone has it now.
This problem came back with the Vulkan plugin, as laptops having very old drivers (e.g. from 2014) with GPUs that were perfectly capable of running Vulkan would crash due to missing system DLLs.
Furthermore, if the GPU cannot do Vulkan, Ogre would also crash.
We added the keyword PluginOptional to the Plugins.cfg file. With this, Ogre will try to load OpenGL, D3D11, Metal and/or Vulkan; and if these plugins fail to load, they will be ignored.
Make sure to update your Plugins.cfg to use this feature to provide a good experience to all of your users, even if they’ve got old HW or SW.
Other relevant information when porting
See What’s New in Ogre 2.3 from the manual for detailed info.
Also see Root Layouts section if you are customizing Hlms implementations and want to support Vulkan.
The future: Ogre 2.4
We already have a ticket tracking 2.4 roadmap.
Rather than rendering features, Ogre 2.4 will be focusing on robusting its source code base. There is a lot of code debt which needs to be addressed.
Most notably:
- We will change the project from “Ogre” to “Ogre-Next”. The PR is already on its way and has been sitting in the backburner because we didn’t want to risk such a potentially breaking change so close to 2.3’s release. This change will allow installing Ogre 1.x and Ogre-Next side by side at the same time
- Move to C++11 and up
- Users may remembers my stance on C++11 adoption. Since then, while sadly the bloat is still there (literally compiling with C++98 is just faster because std headers bring in a lot of unnecessary baggage) HW has become faster, compilers did make some marginal improvements on build speeds, and most importantly we’re seeing more trouble maintaining C++98/03 support than just moving to C++11.
- Additionally, we’ve long been wanting to use some of the C++11 (and up) built in features such as
overridekeyword which help improve code quality.
- Remove dead and deprecated code
- Remove Boost (all Boost functionality we depended on can be found on the STL in C++11)
As for features, we will work on those needed by CIVCT:
- Metal will start using Root Layouts, just like Vulkan. This will allow us to support a lot more textures and UAVs per shader.
- Hlms implementations have a lot of duplicate Samplers for per-pass resources. We must merge them because on D3D11 CIVCT runs out of the limit of 16 samplers.
About the 2.3.0 release
For a full list of changes see the Github release
Source and SDK is in the download page.
Discussion in forum thread.
Thanks to Open Source Robotics Corporation for sponsoring CIVCT feature for their Ignition Project
Ogre-Next 2.2.6 Cerberus and 2.1.2 Baldur released
These are maintenance releases. Little effort should be spent porting to these newer versions.
About the 2.2.6 release
For a full list of changes see the Github release
Source and SDK is in the download page.
About the 2.1.2 release
For a full list of changes see the Github release
Source and SDK is in the download page.
Discussion in forum thread.
Ogre 13.2 released
![]() Ogre 13.2.0 was just released. This “holiday release” contains mostly bugfixes, however there are also some notable additions.
Ogre 13.2.0 was just released. This “holiday release” contains mostly bugfixes, however there are also some notable additions.
Table of Contents
Vulkan RenderSystem
The elephant in the Room is likely the addition of the Vulkan Rendersystem – as was announced earlier. Contrary to my expectation, progress was quite smooth though. This means that all basic features are already in place and the RTSS and Terrain Components support Vulkan too. Therefore, the Vulkan RenderSystem is now tagged [BETA] instead of [EXPERIMENTAL]. Still, some more advanced features are currently missing.

Depending on your usage, you might be able to already port your application – at least you can already start familiarizing with it. There are two caveats though..
Buffer updates
Currently Ogre does not try to hide the asynchronicity of Vulkan from the user and rather lets you run into rendering glitches.
The general idea of Vulkan is that you have multiple images in flight to keep the GPU busy. This means that we submit the work for the next frame without waiting for the current frame to finish.
This part hits you as soon as try to update vertex data. If the GPU is not yet done processing it, you will get rendering glitches. Particularly, your rendering will be broken if you update the data each frame.
The solution here is to either implement triple-buffering yourself or discard the buffer contents on update, which will give you new memory on Vulkan. The Ogre internals have been updated accordingly and ideally also improve performance on all other rendersystems.
Rendering interruption
Closely related to the above is rendering interruption. This means that after the first Renderable was submitted for the current frame (i.e. RenderSystem::_render has been called), you decide to load another Texture or update a buffer.
As we dont know whether the update affects the current Frame, we would need to interrupt the rendering, do the upload and continue where we left off. While certainly possible, we just throw an exception right now. Typically, it is much easier to just schedule your buffer updates before rendering kicks off, than ordering things mid-flight. And this is faster too.
Using GLSLang with GL3+
As the RTSS was extended to generate SPIRV compatible GLSL for Vulkan, it was natural to enable this path for GL3+ as well. If the gl_spirv profile is supported, you can now call
mShaderGenerator->setTargetLanguage("glslang");to use the glslang reference compiler instead of whatever your GL driver would do.
HiDPi support in Overlays
Some dangling threads in Overlays were fixed and you can now call
Ogre::OverlayManager::getSingleton().setPixelRatio(appContext.getDisplayDPI()/96);which will scale up the UI appropriately and generate higher resolution Fonts. The magic 96 means 96 DPI which is the common setting of all Monitors up to FullHD.
Depth of Field Sample
I have updated the dormant DoF compositor code we had in Ogre to actually do something.
The sample builds upon the code of DWORD flying around the forums and implements the following technique by Thorsten Scheuermann.

Upcoming Global Illumination improvements in Ogre-Next
Note: This work is being sponsored by Open Source Robotics for the Ignition Project
Ogre-Next offers a wide amount of Global Illumination solutions.
Some better than others, but VCT (Voxel Cone Tracing) stands out for its high quality at an acceptable performance (on high end GPUs).
However the main problem right now with our VCT implementation is that it’s hard to use and needs a lot of manual tweaking:
- Voxelization process is relatively slow. 10k triangles can take 10ms to voxelize on a Radeon RX 6800 XT, which makes it unsuitable for realtime voxelization (only load time or offline)
- Large scenes / outdoors need very large resolution (i.e. 1024x32x1024) or just give up to large quality degradations
- It works best on setting up static geometry on a relatively small scene like a room or a house.
If your game is divided in small sections that are paged in/out (i.e. PS1 era games like Resident Evil, Final Fantasy 7/8/9, Grim Fandango) VCT would be ideal.
But in current generation of games with continous movement over large areas, VCT falls short, not unless you do some insane amount of tricks.
So we’re looking to improve this and that’s where our new technique Cascaded Image VCT (CIVCT… it wouldn’t be a graphics technique if we didn’t come up with a long acronym) comes in:
- Voxelizes much faster (10x to 100x), enabling real time voxelization. Right now we’re focusing on static meshes but it should be possible to support dynamic stuff as well
- User friendly
- Works out of the box
- Quality settings easy to understand
- Adapts to many conditions (indoor, outdoor, small, large scenes)
That would be pretty much the holy grail of real time GI.
Step 1: Image Voxelizer
Our current VctVoxelizer is triangle based: It feeds on triangles, and outputs a 3D voxel (Albedo + Normal + Emissive). This voxel is then fed to VctLighting to produce the final GI result:

Right now we’re using VctVoxelizer voxelizes the entire scene. This is slow.
Image Voxelizer is image-based and consists in two steps:
- Reuse VctVoxelizer to separately voxelize each mesh offline and save results to disk (or during load time). At 64x64x64 a mesh would need between 2MB and 3MB of VRAM per mesh (and disk space) depending on whether the object contains emissive materials. Some meshes require much lower resolution though. This is user tweakable. You’d want to dedicate more resolution to important/big meshes, and lower resolution for the unimportant ones.
- This may sound too much, but bear in mind it is a fixed cost independent of triangle count. A mesh with a million triangles and a mesh with a 10.000 triangles will both occupy the same amount of VRAM.
- Objects are rarely square. For example desk table is often wider than it is tall or deep. Hence it could just need 64x32x32, which is between 0.5MB and 0.75MB
- Each frame, we stitch together these 3D voxels of meshes via trilinear interpolation into a scene voxel. This is very fast.
This feature has been fast thanks to Vulkan, which allows us to dynamically index an arbitrary number of bound textures in a single compute dispatch.
OpenGL, Direct3D 11 & Metal* will also support this feature but may experience degraded performance as we must perform the voxelization in multiple passes. How much of a degradation depends on the API, e.g. OpenGL actually will let us dynamically index the texture but has a hard limit on how many textures we can bind per pass.
(*) I’m not sure if Metal supports dynamic texture indexing or not. Needs checking.
Therefore this is how it changed:
This step is done offline or at loading time:

This step can be done every frame or when the camera moves too much, or if an object is moved

Downside
There is a downside of this (aside from VRAM usage): We need to voxelize each mesh + material combo. Meaning that if you have a mesh and want to apply different materials, we need to consume 2-3MB per material
This is rarely a problem though because most meshes only use one set of materials. And for those that do, you may be able to get away with baking a material set that is either white or similar; the end results after calculating GI may not vary that much to worth the extra VRAM cost.
Non-researched solutions:
- For simple colour swaps (e.g. RTS games, FPS with multiplayer teams), this should be workaroundeable by adding a single multiplier value, rather than voxelizing the mesh per material
- It should be possible to apply some sort of BC1-like compression, given that the mesh opaqueness and shape is the same. The only thing that changes is colour; thus a delta colour compression scheme could work well
Trivia
At first I panicked a little while developing the Image Voxelizer because the initial quality was far inferior than that of the original voxelizer.
The problem was that the original VCT is a ‘perfect’ voxelization. i.e. if a triangle touches a single voxel, then that voxel adopts the colour of the triangle. Its neighbour voxels will remain empty. Simple.
That results in a ‘thin’ voxel result.
However in IVCT, voxels are interpolated into a scene voxel that will not match in resolution and may be arbitrarily offsetted by subpixels. It’s not aligned either.
The result is that certain voxels have 0.1, 0.2 … 0.9 of the influence of the mesh. This generates ‘fatter’ voxels.
In 2D we would say that the image has a halo around the contours
Once I understood what was going on, I tweaked the math to thin out these voxels by looking at the alpha value of the interpolated mesh and applying an exponential curve to get rid of this halo.
And now it looks very close to the reference VCT implementation!
Step 2: Row Translation
We want to use cascades (a similar concept from shadow mapping, i.e. Cascaded Shadow Maps. In Ogre we call it Parallel Split Shadow Maps but it’s the same thing) concentric around the camera.
That means when the camera moves, once the camera has moved too much, we must move the cascades and re-voxelize.
But we don’t need to voxelize the entire thing from scratch. We can translate everything by 1 voxel, and then revoxelize the new row:
As the camera wants to move, once it moved far enough, we must translate the voxel cascade
Given that we only need to partially update the voxels after camera movement, it makes supporting cascades very fast
Right now this step is handled by VctImageVoxelizer::partialBuild
Step 3: Cascades
This step is currently a work in progress. The implementation is planned to have N cascades (N user defined). During cone tracing, after we reach the end of a cascade we move on to the next cascade, which covers more ground but has coarser resolution, hence lower quality.
Wait isn’t this what UE5’s Lumen does?
AFAIK Lumen is also a Voxel Cone Tracer. Therefore it’s normal there will be similarities. I don’t know if they use cascades though.
As far as I’ve read, Lumen uses an entirely different approach to voxelizing which involves rasterizing from all 6 sides, which makes it very user hostile as meshes must be broken down to individual components (e.g. instead of submitting a house, each wall, column, floor and ceiling must be its own mesh).
With Ogre-Next you just provide the mesh and it will just work (although with manual tunning you could achieve greater memory savings if e.g. the columns are split and voxelized separately).
Wait isn’t this what Godot does?
Well, I was involved in SDFGI advising Juan on the subject, thus of course there are a lot of similarities.
The main difference is that Godot generates a cascade of SDFs (signed distance fields), while Ogre-Next is generating a cascade of voxels.
This allows Godot to render on slower GPUs (and is specially better at specular reflections), but at the expense of accuracy (there’s a significant visual difference when toggling between Godot’s own raw VCT implementation and its SDFGI; but they both look pretty) but I believe these quality issues could be improved in the future.
Having an SDF of the scene also offers interesting potential features such as ‘contact shadows’ in the distance.
Ogre-Next in the future may generate an SDF as well as it offers many potential features (e.g. contact shadows) or speed improvements. Please understand that VCT is an actively researched topic and we are all trying and exploring different methods to see what works best and under what conditions.
The underlying techniques aren’t new, but what made it possible are the new APIs and the raw power provided by current generation of GPUs that can keep up with them (although the current GPU shortage might delay the widespread adoption of these techniques).
Since this technique will be used in Ignition Gazebo for simulations, I had to err on the side of accuracy.
When is it coming?
CIVCT isn’t done yet but hopefully it should be ready 1-2 more weekends (I can only work on this during the weekends). Maybe 3? (I hope not!). I want to release Ogre-Next 2.3 RC0 in the meantime, and when CIVCT is ready a proper Ogre-Next 2.3 release.
The reason it’s taking so little time is because we’re improving on our existing technology and reusing lots of code. We’re just changing a few details to make it faster and more use friendly now that Vulkan gives us that freedom (but again, we plan on supporting this feature on all our API backends).
These improvements are currently living in vct-image branch but has no sample yet showcasing it as it is WIP.
Btw! Remember there is an active poll to decide on Ogre-Next 2.3 name. Don’t forget to vote!
Cast your vote to decide on Ogre-Next 2.3 name!
After the first round of candidates to decide on a name for Ogre-Next 2.3, we’ve got to the final round!
Please cast your vote to decide the name for Ogre-Next 2.3 (and yes, an official release is coming soon!). Whichever wins will become the new name for Ogre-Next 2.3